【システム監視】ZabbixでLinuxサーバの死活監視・リソース監視
前回の記事では、Zabbixのインストールまでやりました。
次は、実際にZabbixに監視設定を入れて、監視対象機器の異常を検知できるようにします。
今回は、Linuxサーバの基本的な死活監視、リソース周りの監視設定を入れていきます。
目次
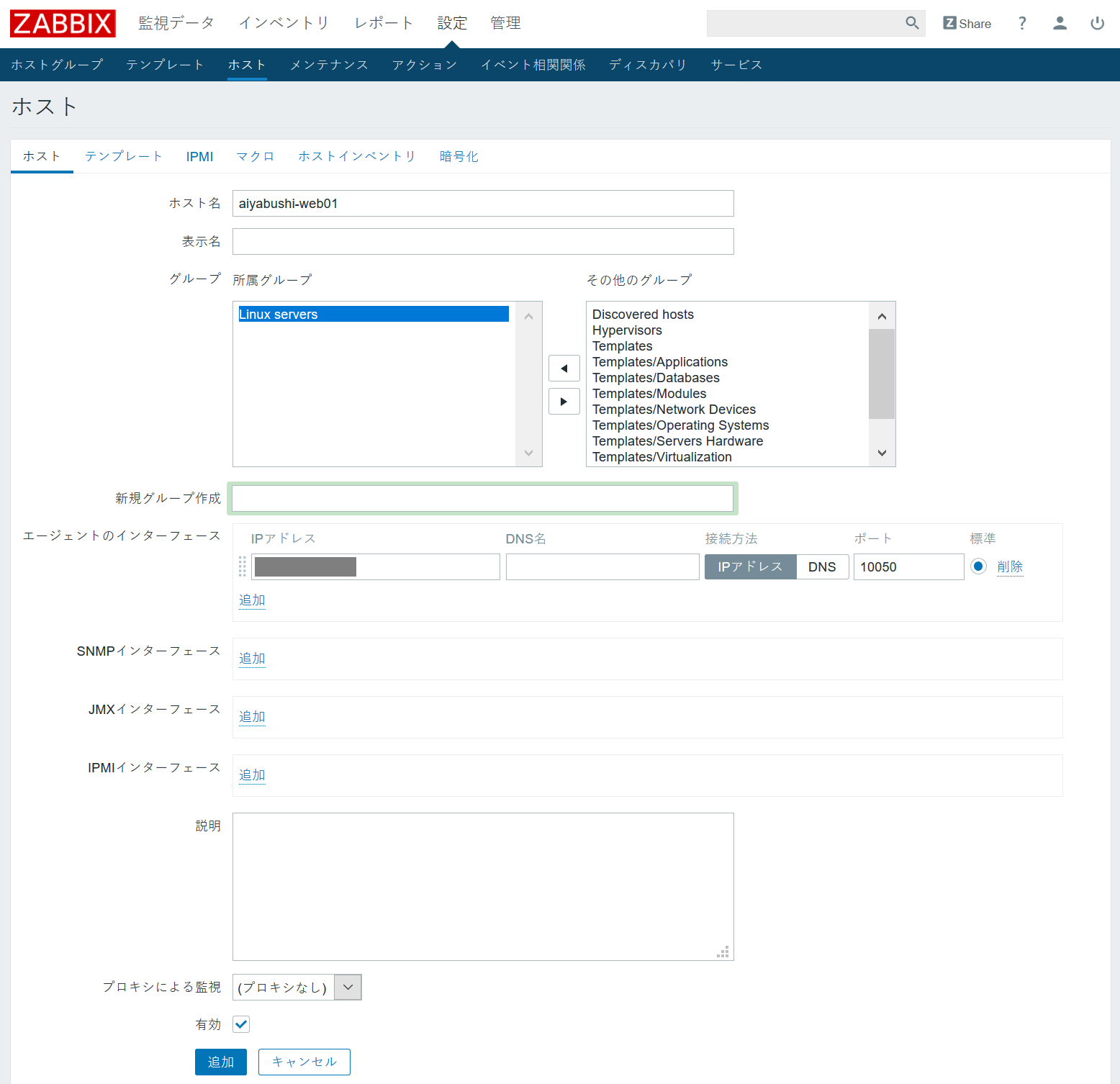
監視対象機器の追加(ホスト設定)
まずは、監視対象とする機器をZabbix管理画面で追加していきます。
Zabbixでは、監視対象機器を「ホスト」と呼びます。
- 管理画面の「設定」⇒「ホスト」から、「ホストの作成」をクリック。
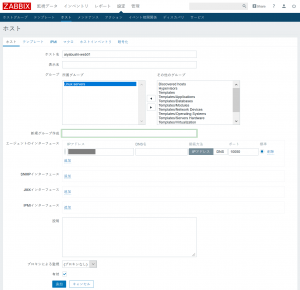
- ホスト名を追加。
グループは元々あるものを利用するか、新規に作って管理しやすいようにします。
監視対象がサーバ(Zabbixエージェントがインストール済のもの)は、エージェントの項目にIPアドレスを追加。
監視対象がネットワーク機器(Zabbixエージェントではなく、SNMPで情報取得するもの)は、エージェントのインターフェース欄を削除した上で、SNMPインタフェースを追加してIPアドレスを追加。
- 「追加」をクリックで、監視対象が保存されます。
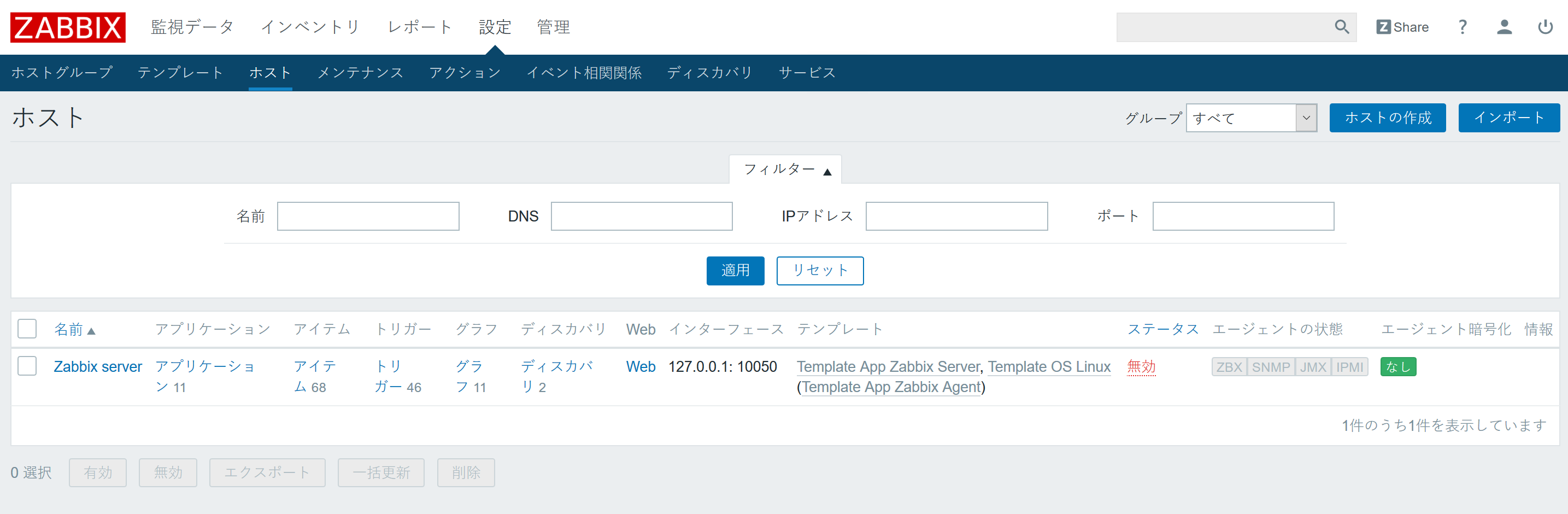

最初から用意されている監視設定を利用(テンプレート設定)
監視項目をひとまとめにして、いろいろな監視対象で使いまわせるようにしたものがテンプレートです。
Zabbixには最初からいろいろなテンプレートが、主要な監視項目とセットで用意されています。
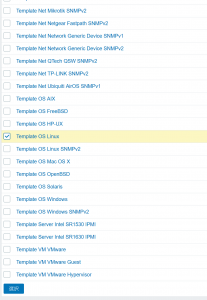
自分で監視項目を作るのは面倒、とりあえず出来合いの設定で監視できればよいということであれば、「Template OS Linux」「Template OS Windows」などをホストに対してそのまま適用すれば、簡単に監視を始めることができます。
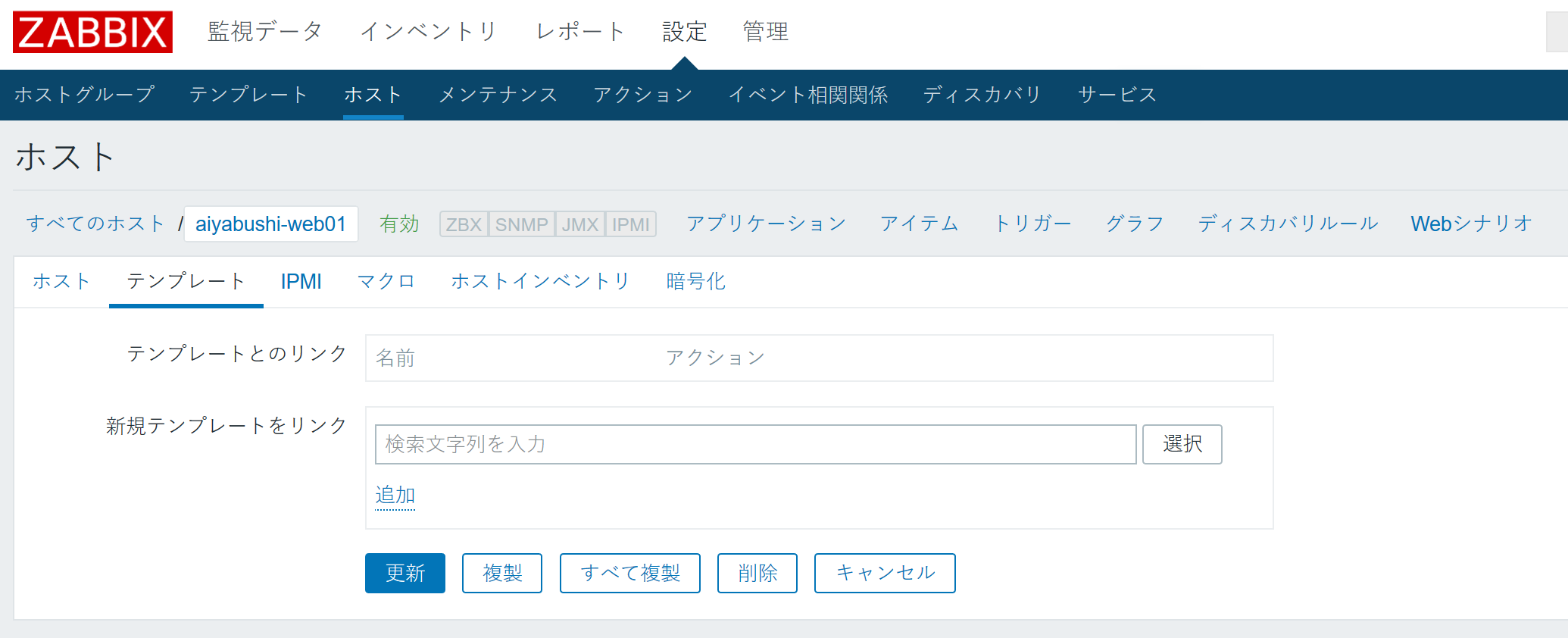
- 管理画面の「設定」⇒「ホスト」から、対象機器を選択。
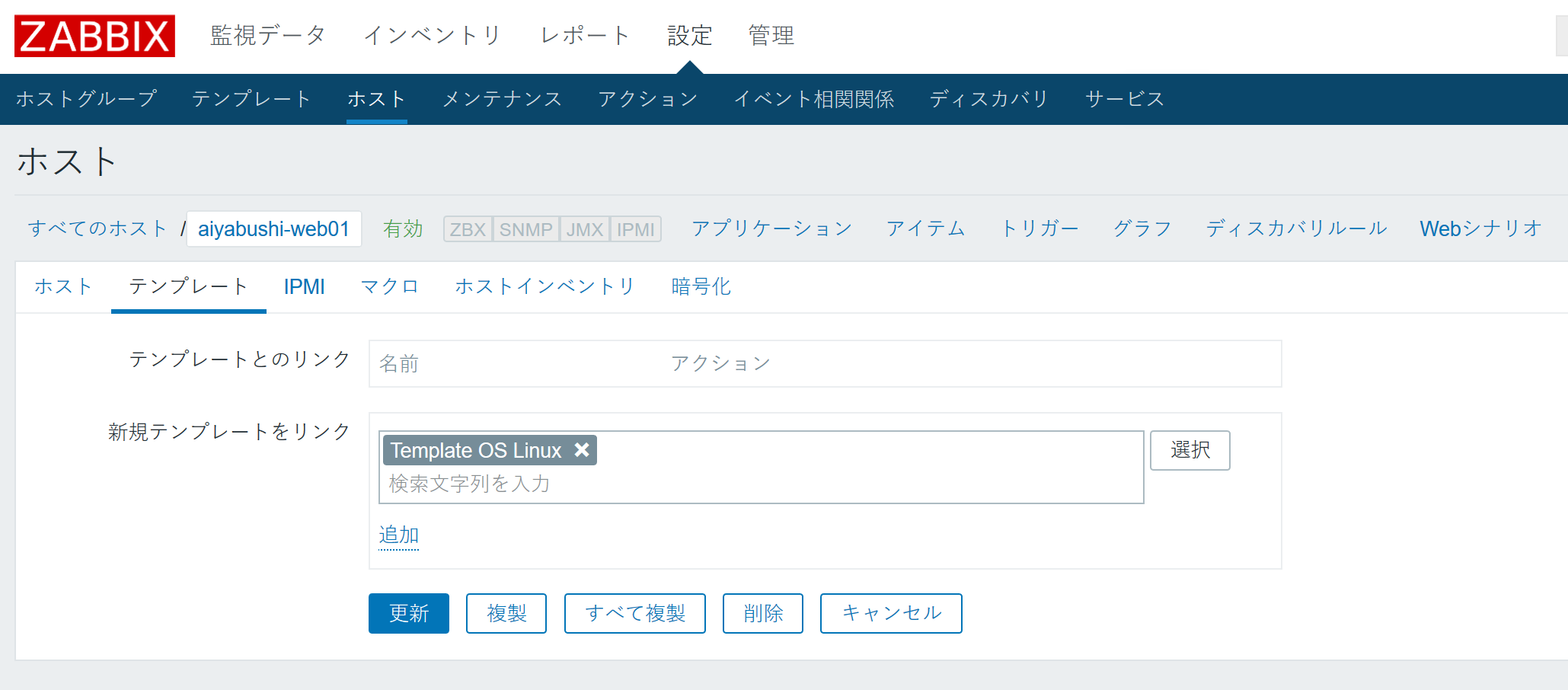
- 設定欄の上にある「テンプレート」を選択。
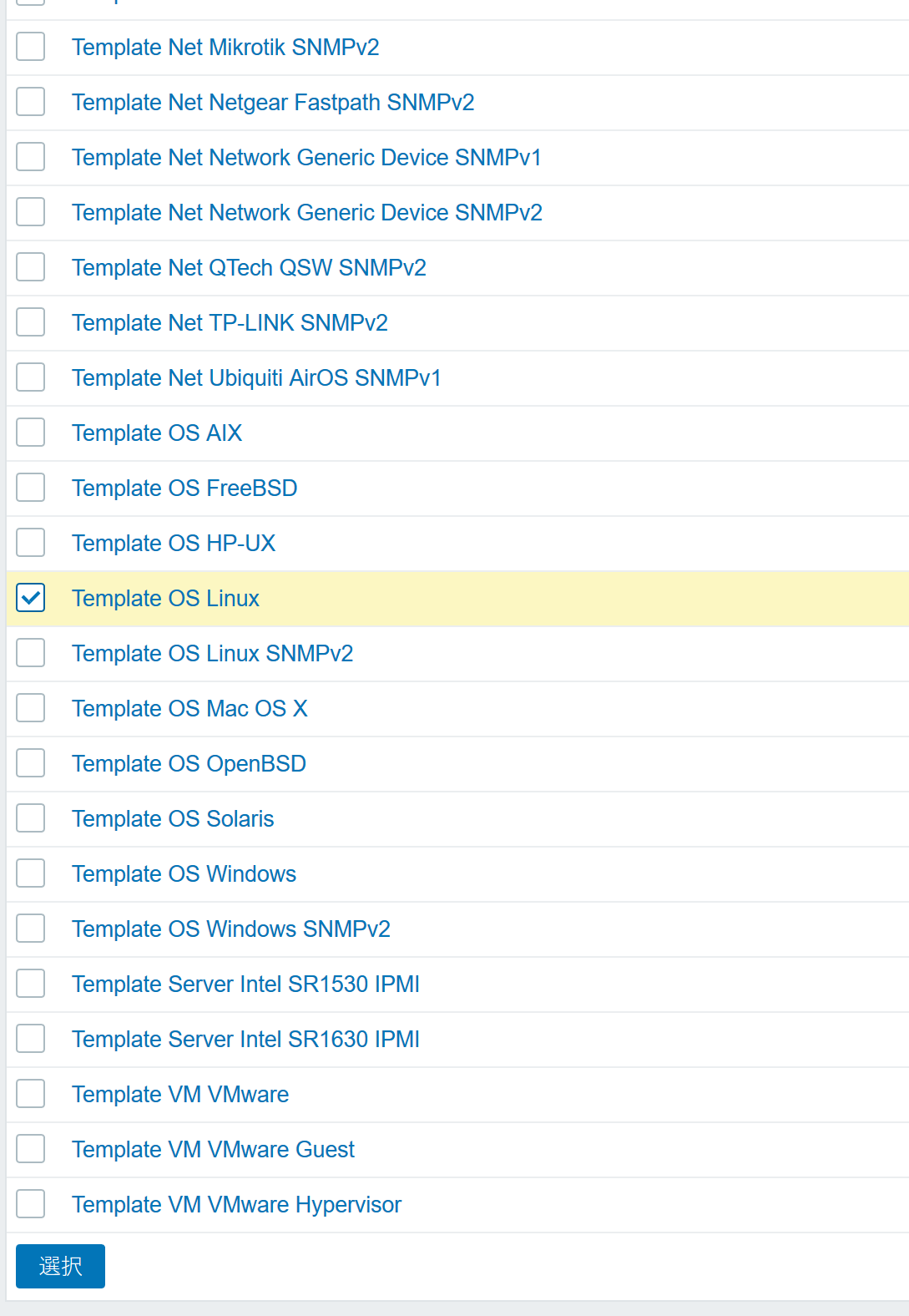
- 「新規テンプレートをリンク」の欄にある「選択」ボタンを選択。
- 対象のテンプレートにチェックを入れて、「選択」をクリック。
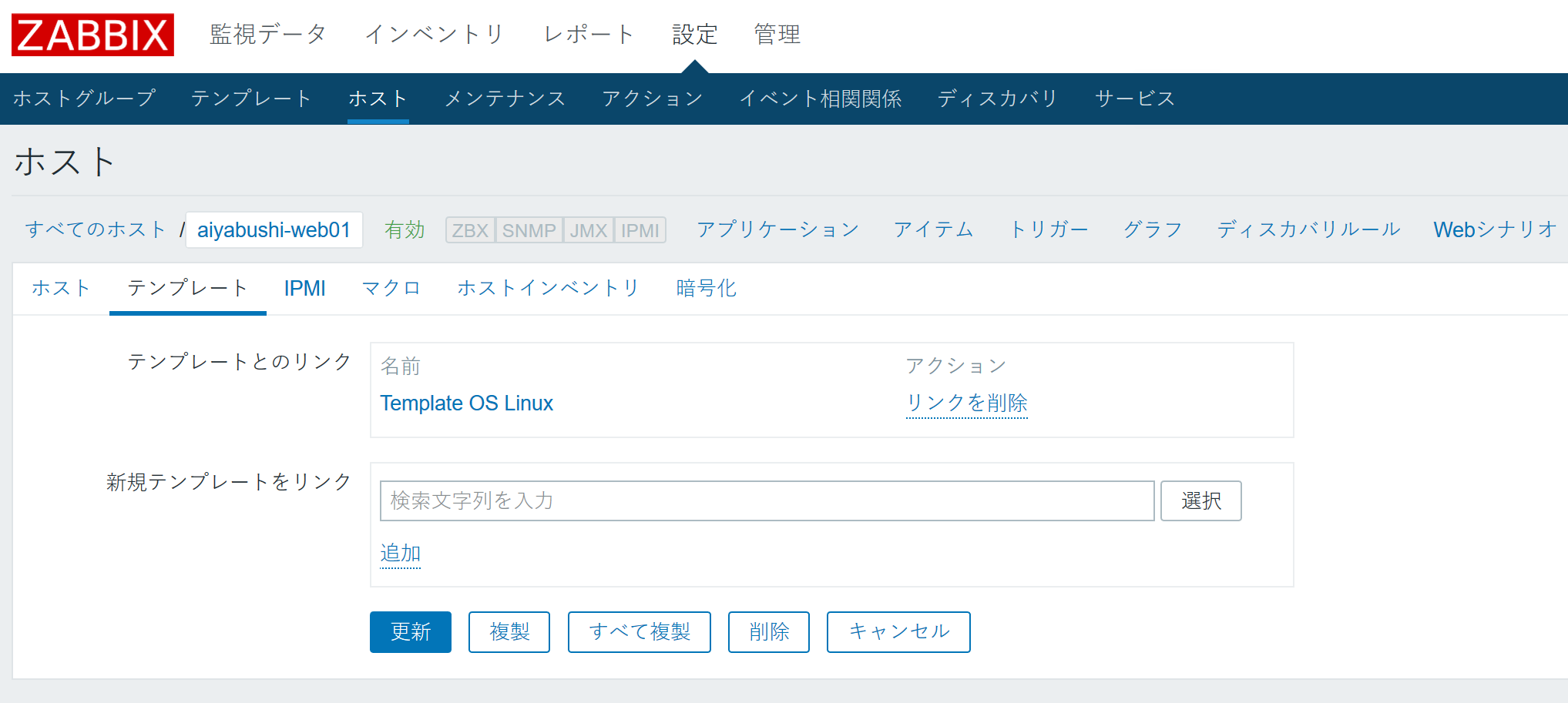
- 「追加」をクリック。
- テンプレートとのリンクに追加されたことを確認して、「更新」をクリック。
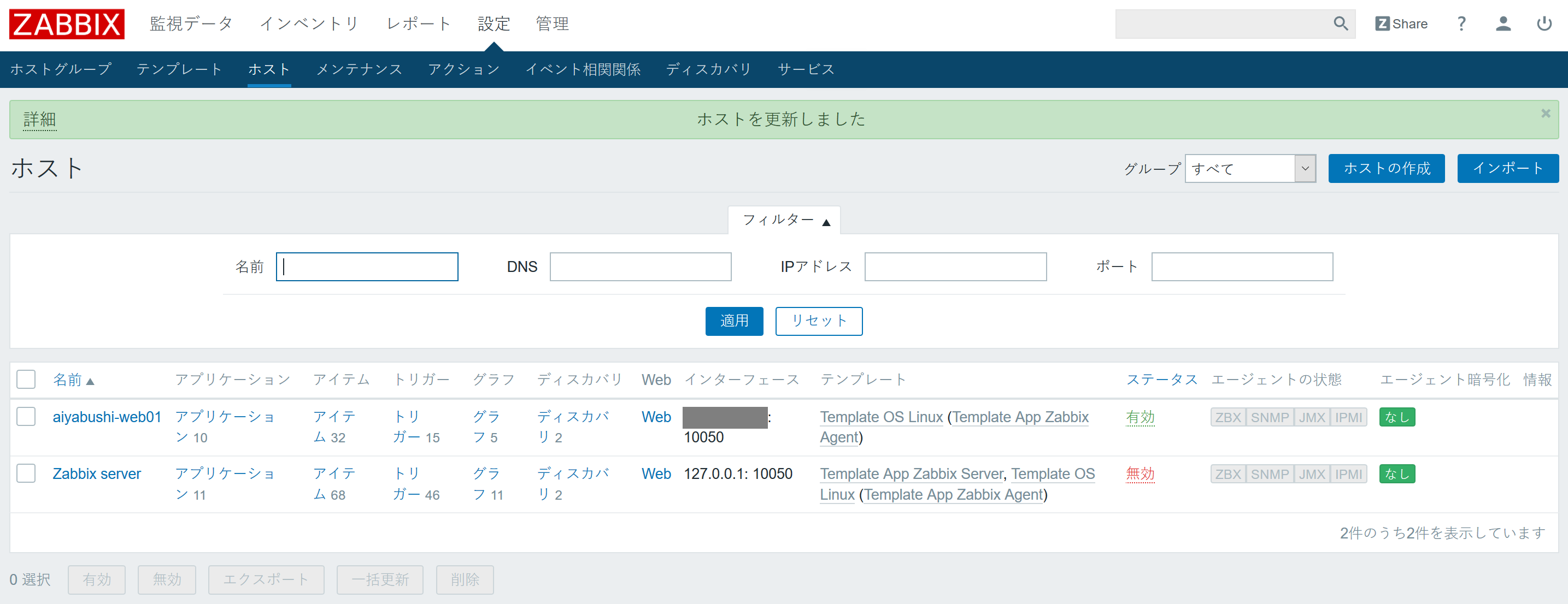
- 設定が反映されます。
- 管理画面の「監視データ」⇒「グラフ」を開き、対象のグループ、ホスト、グラフを選択すると、監視が始まったことを確認できます。
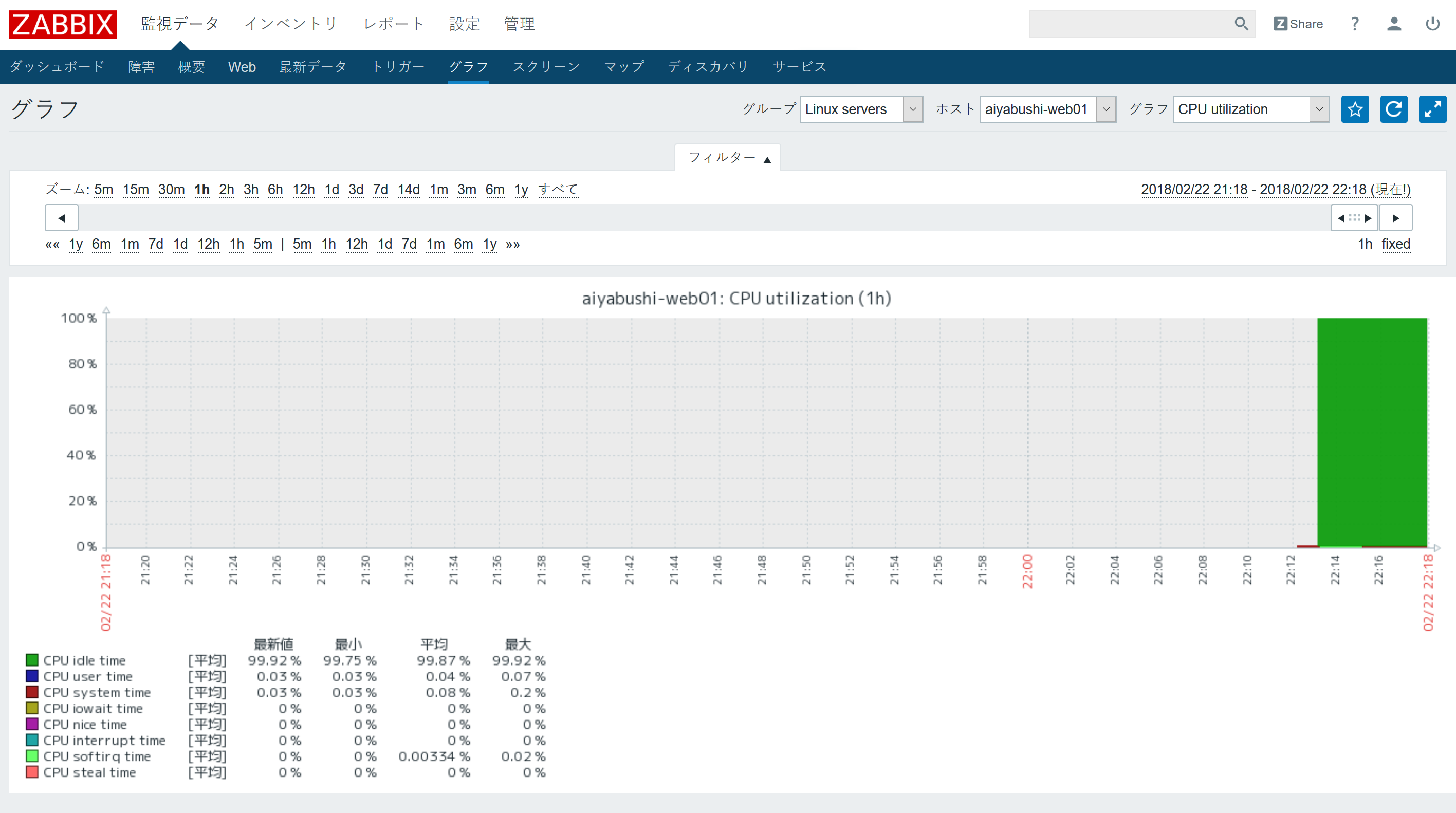
監視項目の追加(アイテム・トリガー設定)
Zabbixでは、監視項目を「アイテム」、警告を発する条件を「トリガー」といいます。
自分でアイテム・トリガーを追加したい場合、ホストに直接追加する方法と、テンプレートを作ってその中に追加する方法の2種類があります。
ホスト別に設定をカスタマイズしたい場合はホストに直接追加して、同じ監視設定を多数のホストで使いまわしたい場合はテンプレートを利用すると良いと思います。
以下は、ホストに直接追加する場合の方法です。
- 対象ホストの設定画面を開き、画面上の「アイテム」リンクをクリックすると、アイテム一覧画面になります。
「アイテムの作成」をクリック。
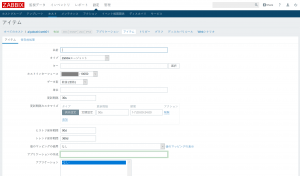
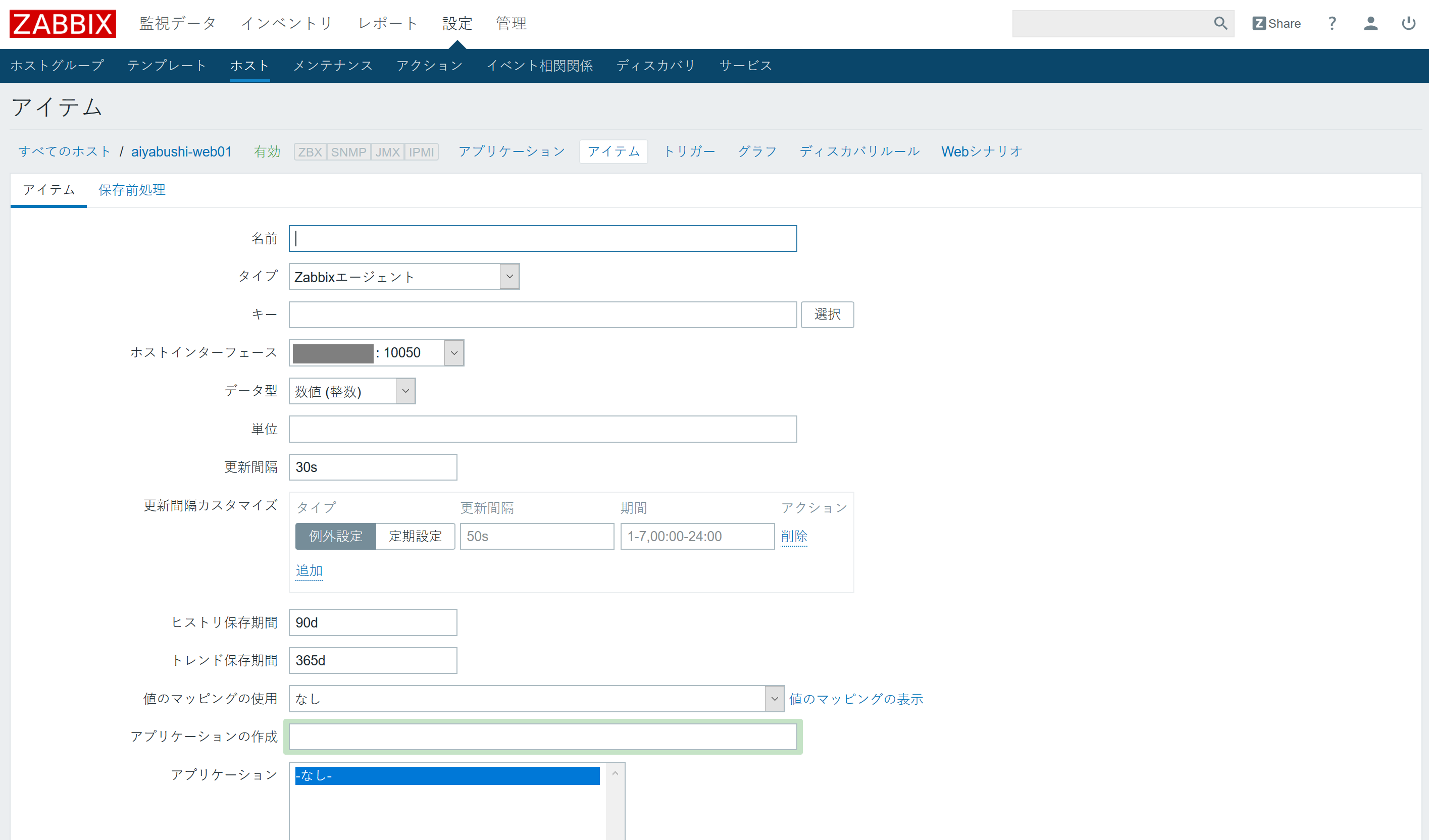
- 「名前」にアイテムの名前を設定。以下で、監視項目別に「キー」「データ型」などを設定していきます。
「キー」欄の横にある「選択」をクリックすると、あらかじめ用意されている各種キーを確認できます。キーを選択してから、用途に合わせて引数を編集することで監視が反映されます。
「更新間隔」は、監視する間隔を秒単位で指定できます。
- 対象ホストの設定画面に戻り、画面上の「トリガー」リンクをクリックするとトリガー一覧画面に行けます。
「トリガーの作成」をクリック。
- 「深刻度」で警報の重要度を自由に設定できます。
「条件式」で、対象のアイテムと、警報を発する条件を指定します。
Ping死活監視
サーバに対してPing(ICMPパケット)を送信し、応答があれば正常、無反応なら異常と判断します。
キー「icmpping」は、Ping応答があったときに1、無反応なら0です。
以下の内容で設定すれば、1回でも無反応だった事象を検知できます。
- アイテム
- タイプ: シンプルチェック
- キー: icmpping
- データ型: 数値(整数)
- トリガー
- 関数: 期間Tの値の最大値=N
- 最新の(T): 1カウント
- N: 0
CPU空き率監視
CPUに高負荷が発生していないか監視します。
以下のアイテムは、全コアの平均であるall、空き率を表すidle、直近5分の平均であるavg5を引数にした例です。
トリガーでは、N=10以下(つまり使用率90%以上)になったときに警告を発します。
- アイテム
- タイプ: Zabbixエージェント
- キー: system.cpu.util[all,idle,avg5]
- データ型: 数値(浮動小数)
- トリガー
- 関数: 期間Tの値の最大値<N
- 最新の(T): 1カウント
- N: 10
メモリ空き率監視
メモリの使用状況を監視します。
Linuxサーバの場合、平時から多めにメモリをキャッシュとして確保しておく仕様のため、実際のメモリの空き率をそのまま監視するのは好ましくありません。
ここでは、inactive(未使用分)、cached(キャッシュ)、free(未割当分)の合計の割合を表すpavailableを引数に指定します。
トリガーは、N=10以下(使用率90%以上)になったときに警告を発します。
- アイテム
- タイプ: Zabbixエージェント
- キー: vm.memory.size[pavailable]
- データ型: 数値(浮動小数)
- トリガー
- 関数: 期間Tの値の最大値<N
- 最新の(T): 1カウント
- N: 10
ディスク空き率監視
ディスクの使用状況を監視します。
以下では、対象を「/」(ルートパーティション)、モードに「pfree」(空き率)を引数に指定しています。
トリガーは、N=10以下(使用率90%以上)になったときに警告を発します。
- アイテム
- タイプ: Zabbixエージェント
- キー: vfs.fs.size[/,pfree]
- データ型: 数値(浮動小数)
- トリガー
- 関数: 期間Tの値の最大値<N
- 最新の(T): 1カウント
- N: 10
プロセス監視
特定のプロセスが動作しているか監視します。
psコマンドを実行したときに表示されるプロセス名を指定します。
以下の例では、httpdプロセスが起動しているか監視しています。
- アイテム
- タイプ: Zabbixエージェント
- キー: proc.num[httpd]
- データ型: 数値(整数)
- トリガー
- 関数: 期間Tの値の最大値<N
- 最新の(T): 1カウント
- N: 1
サーバ再起動監視
サーバが突然再起動したときに気づけるようにします。
サーバが再起動すると、uptimeの値(秒単位)が0にリセットされるので、例えば300以内なら再起動直後とみなします。
- アイテム
- タイプ: Zabbixエージェント
- キー: system.uptime
- データ型: 数値(整数)
- トリガー
- 関数: 期間Tの値の最大値<N
- 最新の(T): 1カウント
- N: 300
ポート死活監視
サーバのポートを監視できます。
以下の例は、Webサーバなどを公開している場合に、サーバのTCP80番ポートなどを監視する設定です。
httpアクセスの待ち受けが正しく機能しているか確認できます。
成功が1、失敗は0の値が返ります。
- アイテム
- タイプ: シンプルチェック
- キー: net.tcp.service[http,,80]
- データ型: 数値(整数)
- トリガー
- 関数: 期間Tの値の最大値=N
- 最新の(T): 1カウント
- N: 0
まとめ
以上で、Linuxサーバの基本的な監視設定ができました。
今後は、さらにサーバ以外のネットワーク機器の設定なども入れて監視環境を充実させたり、異常を検知した際にメールなどで通知する仕組みを整えていこうと思います。
